性能度量
对学习器的泛化性能进行评估
在预测任务中,给定样例集$D=\lbrace (x_1,y_1),(x_2,y_),…,(x_n,y_n)\rbrace$,其中$y_i$是$x_n$的真实标记,估计学习器的性能就是把预测的结果$f(x)$与实际值进行比较
指标
回归任务中常用的是“均方误差”:
下面介绍分类任务中常用的度量指标
1. 错误率与精度
错误率就是分类错误的样本数占样本总数的比例
精度就是$1-E$
2. 准确率、召回率和F1
错误率和精度不能满足所有任务的需求
比如在web搜索中,我们经常会关心,检索出来的信息有多少是用户关心的,或者用户真正关心的数据中有多少被检索出来了,所以引入“准确率”和“召回率”
分类据结果的混淆矩阵为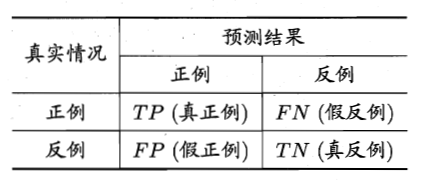
准确率和召回率定义为:
准确率和召回率是一组矛盾的度量,一般准确率高时,召回率往往偏低;召回率高时,准确率往往偏低
如何理解二者之间的矛盾呢,我们依然沿用上面的例子,如果我们想尽可能多地返回用户关心的信息,就可以返回大量的信息,此时用户关心的结果可能都被选上了,但是也返回了大量用户不关心的信息,准确率较低;反之,如果我们希望返回的信息中心用户关心的比例比较高,就可以只返回那些有把握的信息,但这样就会漏掉不少可能也是用户关心的信息,也就是召回率比较低。
下图为P-R曲线,可以直观的反映准确率和召回率之间的矛盾,评估模型时,可以根据曲线下方面积进行模型比较,面积大者效果比较好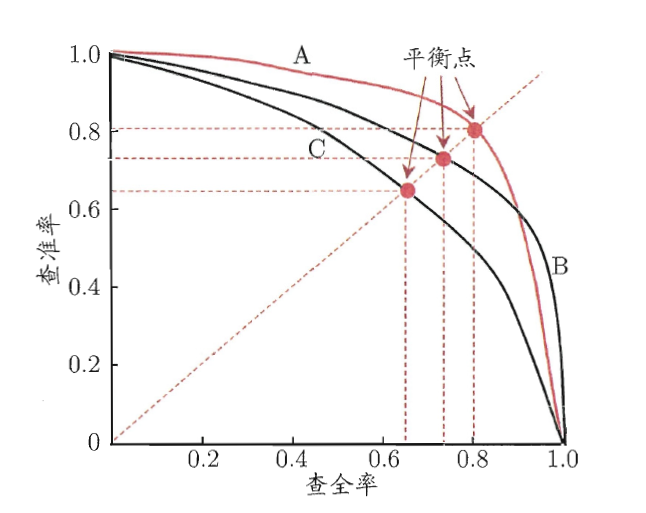
在实际应用时中,我们可以结合实际情况,权衡两个指标的重要程度,因此引入$F_{\beta}$指标:
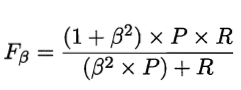
$\beta>1$时准去率相对更重要,$\beta<1$召回率相对更重要。当$\beta=1$时,就是我们常用的F1度量形式
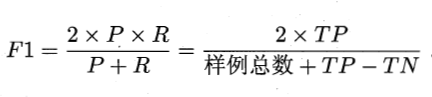
3. ROC、AUC
用途
体现了“一般情况下”泛化性能的好坏
很多机器学习器是为测试样本产生一个实值或概率预测,然后再设定一个阈值t,高于这个阈值就预测为正类,反之预测为负类。针对不同的任务,选取的阈值t也不一样,ROC体现了综合考虑学习器在不同任务下的“期望泛化能力”的好坏
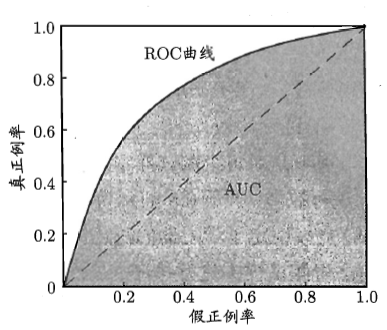
ROC曲线
先看看ROC曲线长什么样
横轴:“假正例率(false positive rate)”——负样本预测成正类的比例
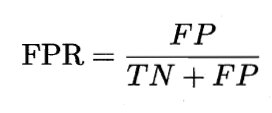
纵轴:“真正例率(true positive rate)”——正样本预测成正类的比例
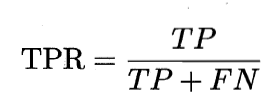
为了方便理解公式,再贴一下混淆矩阵
现在来解释一下ROC曲线:曲线上的每一点都是一个(TPR,FPR)点对,表示的是对于一个模型,选择一个阈值t作为分类的依据,得到的假正例率和真正例率构成的点对。
(0,0)表示所有样本都预测成负类的情况
(1,1)表示所有样本都预测成正类的情况
(0,1)表示所有样本都预测正确的情况
虚线表示随机预测的情况
绘制ROC曲线
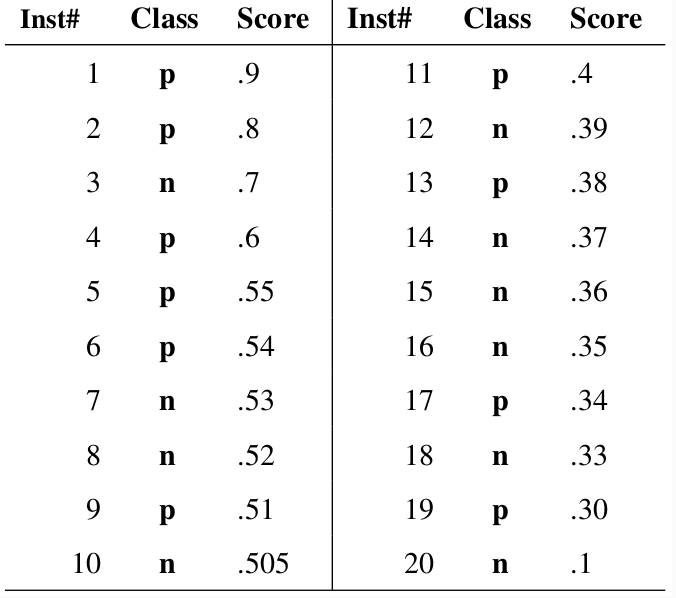
- 给出20个测试样本
- “class”为样本的真实属性
- “score”是预测值,表示样本属于正样本的概率
步骤:
- 从高到低依次选取“score”作为阈值,概率大于该阈值的预测成正类,反之预测成反类
- 每次选取一个不同的阈值会都会得到一个(FPR,TPR)点对,即ROC曲线上的一点。这样一来,我们一共得到了20组(FPR,TPR)点对,将它们画在ROC曲线的结果如下图:
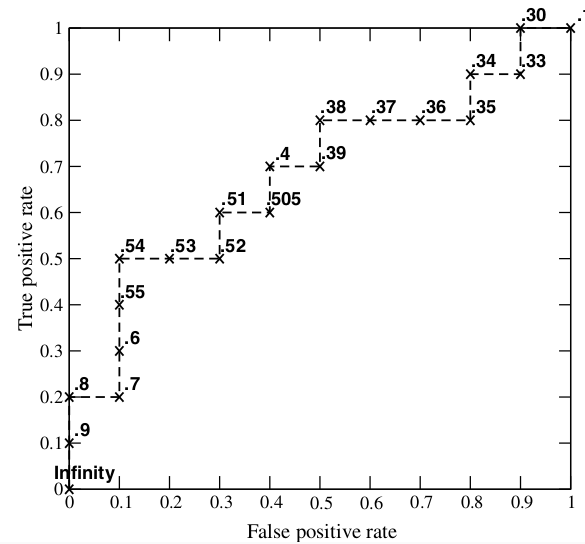
- 当我们将阈值设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。
- 当阈值的取值越多,ROC曲线越平滑。
AUC(area under ROC curve)
- AUC的值就是处于ROC曲线下方部分面积的大小
- 通常,AUC的值介于0.5到1.0之间,越接近1表示模型的泛化能力越好
- 较大的AUC代表了较好的performance
AUC的计算方法
形式化地看,AUC考虑的是样本预测的排序质量,也就是在M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score(正样本排在负样本前面)
- 从误差方面入手,即由模型计算出来的分数,负样本比正样本高的概率。如果给定$m_+$个正例和$m_-$个负例,令$D_+$和$D_-$分别表是正、负例集合,则排序“损失”定义为
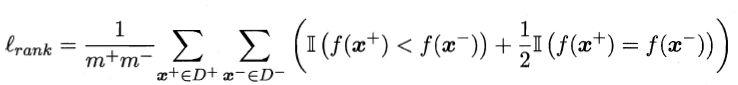
即考虑每一对正、反例对,如果正例的预测值小于反例,则记一个罚分,如果相等,记0.5个罚分。对应于RUC曲线上半部分的面积,那么RUC曲线下半部分的面积:
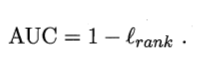
- 第二种方法实际上和上述方法是一样的,但是复杂度减小了。
- 首先对score从大到小排序
- 然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推
- 然后把所有的正类样本的rank相加,再减去正类样本的score为最小的那M个值的情况。
- 得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。
- 然后再除以M×N。即
另外,特别需要注意的是,再存在score相等的情况时,对相等score的样本,需要 赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。
为什么使用ROC
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。下图是ROC曲线和Precision-Recall曲线的对比:
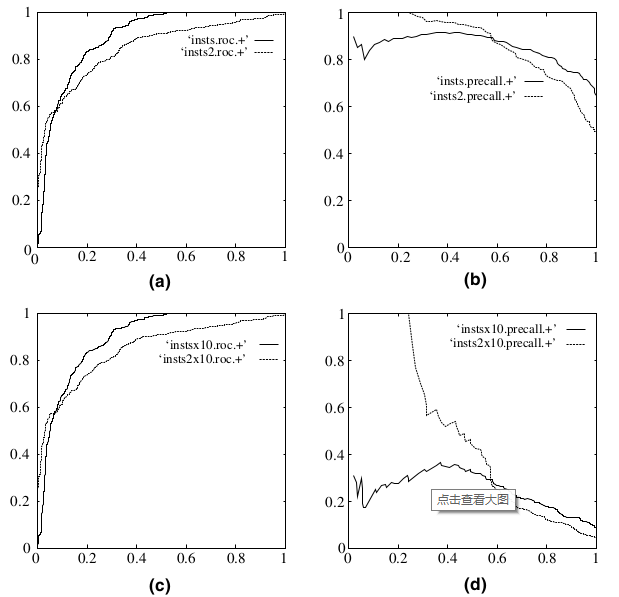
在上图中,(a)和(c)为ROC曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)和(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果。可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线则变化较大。