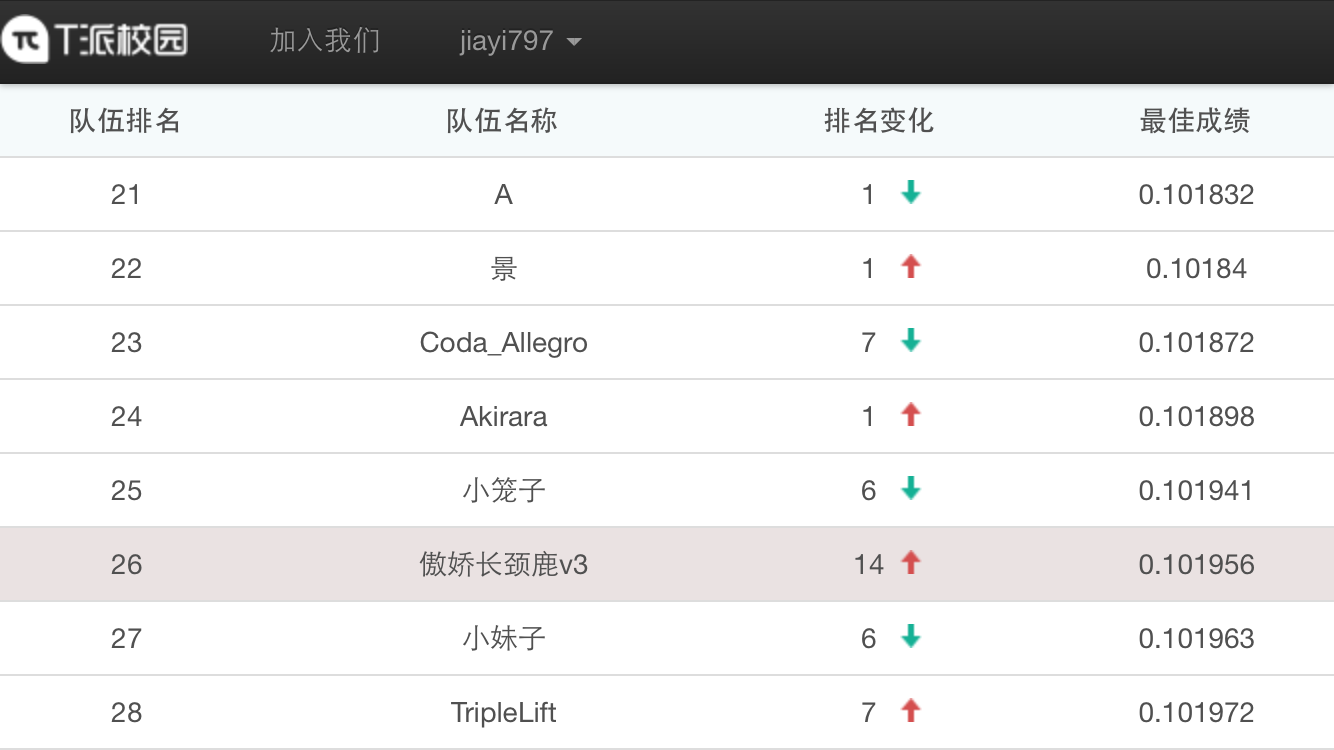
第一届腾讯社交广告算法大赛复赛成绩0.101941,排名26名,在此总结一下。
1. 题目简介
1.1 移动App广告转化率预估
详细赛题见官方网站
计算广告是互联网最重要的商业模式之一,广告投放效果通常通过曝光、点击和转化各环节来衡量,大多数广告系统受广告效果数据回流的限制只能通过曝光或点击作为投放效果的衡量标准开展优化。腾讯社交广告(http://ads.tencent.com)发挥特有的用户识别和转化跟踪数据能力,帮助广告主跟踪广告投放后的转化效果,基于广告转化数据训练转化率预估模型(pCVR,Predicted Conversion Rate),在广告排序中引入pCVR因子优化广告投放效果,提升ROI。
本题目以移动App广告为研究对象,预测App广告点击后被激活的概率:pCVR=P(conversion=1 | Ad,User,Context),即给定广告、用户和上下文情况下广告被点击后发生激活的概率。
总结起来就是说,在业界,大多数广告系统是通过点击率来投放广告的,因为转化追踪起来是比较困难的,然而腾讯凭借平台优势很好地追踪了广告投放之后的转化情况,以此训练转化率预估模型,用转化率来指导广告投放,进而提升ROI。
因此赛题就是给我们17-30号两周(15天)的移动APP广告(投放在移动端的APP广告)数据,让我们训练转化率模型做转化率预估,即预测第31号App广告点击后被激活的概率。
1.2 评估方式:
通过Logarithmic Loss评估(越小越好),公式如下:

其中,
- N是测试样本总数
- 是二值变量,取值为0或1,表示第i个样本的label
- 是模型预测第i个样本label为1的概率
2. 数据
2.1 数据量
数据量:初赛30w/天;决赛300w/天
2.2 数据表
接下来看看给的数据长啥样。
一共给了8张表:
test+train+下面这些:
| 文件类型 | 描述 |
|---|---|
| 用户基础特征文件(user.csv) | 每行代表一个用户,各字段之间由逗号分隔,顺序依次为:“userID,age,gender,education,marriageStatus,haveBaby,hometown,residence”。 |
| 用户App安装列表文件(user_installedapps.csv) | 每行代表一个用户安装的单个App,各字段之间由逗号分隔,顺序依次为:“userID,appID”。特别的,我们提供了截止到第1天0点用户全部的App安装列表。 |
| 用户App安装流水文件(user_app_actions.csv) | 每行代表一个用户的单个App操作流水,各字段之间由逗号分隔,顺序依次为:“userID,installTime,appID”。特别的,我们提供了训练数据开始时间之前16天开始连续30天的操作流水,即第1天0点到第31天0点。 |
| App特征文件(app_categories.csv) | 每行代表一个App,各字段之间由逗号分隔,顺序依次为:“appID,appCategory”。 |
| 广告特征文件(ad.csv) | 每行描述一条广告素材,各字段之间由逗号分隔,顺序依次为“creativeID,adID,camgaignID,advertiserID,appID,appPlatform”。 |
| 广告位特征文件(position.csv) | 每行描述一个广告位,各字段之间由逗号分隔,顺序依次为:“positionID,sitesetID,positionType”。 |
train.csv 训练数据集 :

17到30号共14天点击数据。
每一条训练样本即为一条广告点击日志(点击时间用clickTime表示),样本label取值0或1,其中0表示点击后没有发生转化,1表示点击后有发生转化,如果label为1,还会提供转化回流时间。
每一条数据其中label表示是否转化,经统计转化率大概1/40
数据量:初赛30w/天;决赛300w/天
test.csv 线上测试数据

31号一天数据,字段和test一致,需要预测lable
ad.csv 广告基本特征


这里广告结构分为四级:广告主——推广计划——广告——素材。之后会用到这个层级结构做贝叶斯平滑。
user.csv 用户信息表


就是用户的一些基本特征啦,性别年龄blabla
app_category.csv appID对应的类别信息


就是appID和对应的categoryID,其中类目标签有两层,使用3位数字编码,百位数表示一级类目,十位个位数表示二级类目,如“210”表示一级类目编号为2,二级类目编号为10,类目未知或者无法获取时,标记为0。
position.csv 广告位信息


没啥说的,就是广告位信息,直接merge就行
user_app_actions.csv 用户安装app流水,1——30天的,包含安装时间


用户近期的app安装行为,这里可以挖掘出用户的偏好类别,时间等等。。。
user_installedapps.csv用户历史安装过的app,第一天0点之前的


用户自注册以来安装过的appID,有待挖掘。。。
2.3 总结
总结一下,一共有三类特征,用户特征、广告特征、上下文特征,官网也给了个很好的总结表:
| 特征 | 分类 | 描述 |
|---|---|---|
| 广告特征 | 账户ID(advertiserID) | 腾讯社交广告的账户结构分为四级:账户——推广计划——广告——素材,账户对应一家特定的广告主。 |
| 推广计划ID(campaignID) | 推广计划是广告的集合,类似电脑文件夹功能。广告主可以将推广平台、预算限额、是否匀速投放等条件相同的广告放在同一个推广计划中,方便管理。 | |
| 广告ID(adID) | 腾讯社交广告管理平台中的广告是指广告主创建的广告创意(或称广告素材)及广告展示相关设置,包含广告的基本信息(广告名称,投放时间等),广告的推广目标,投放平台,投放的广告规格,所投放的广告创意,广告的受众(即广告的定向设置),广告出价等信息。单个推广计划下的广告数不设上限。 | |
| 素材ID(creativeID) | 展示给用户直接看到的广告内容,一条广告下可以有多组素材。 | |
| AppID(appID) | 广告推广的目标页面链接地址,即点击后想要展示给用户的页面,此处页面特指具体的App。多个推广计划或广告可以同时推广同一个App。 | |
| App分类(appCategory) | App开发者设定的App类目标签,类目标签有两层,使用3位数字编码,百位数表示一级类目,十位个位数表示二级类目,如“210”表示一级类目编号为2,二级类目编号为10,类目未知或者无法获取时,标记为0。 | |
| App平台(appPlatform) | App所属操作系统平台,取值为Android,iOS,未知。同一个appID只会属于一个平台。 | |
| 用户特征 | 用户ID(userID) | 唯一标识一个用户 |
| 年龄(age) | 取值范围[0, 80],其中0表示未知。 | |
| 性别(gender) | 取值包括男,女,未知。 | |
| 学历(education) | 用户当前最高学历,不区分在读生和毕业生,取值包括小学,初中,高中,专科,本科,硕士,博士,未知 | |
| 婚恋状态(marriageStatus) | 用户当前感情状况,取值包括单身,新婚,已婚,未知。 | |
| 育儿状态(haveBaby) | 用户当前孕育宝宝状态,取值包括孕育中,宝宝0~6个月,宝宝6~12个月,宝宝1~2岁,宝宝2~3岁,育儿但宝宝年龄未知,未知。 | |
| 家乡/籍贯(hometown) | 用户出生地,取值具体到市级城市,使用二级编码,千位百位数表示省份,十位个位数表示省内城市,如1806表示省份编号为18,城市编号是省内的6号,编号0表示未知。 | |
| 常住地(residence) | 最近一段时间用户长期居住的地方,取值具体到市级城市,编码方式与家乡相同。 | |
| App安装列表(appInstallList) | 截止到某一时间点用户全部的App安装列表(appID),已过滤高频和低频App。 | |
| App安装流水 | 最近一段时间内用户安装App行为流水,包括appID,行为发生时间(installTime)和app类别(appCategory),已过滤高频和低频App。 | |
| 注:2~8基于用户个人注册资料和算法自动修正得到,9~10基于用户行为日志统计得到。 | ||
| 上下文特征 | 广告位ID(positionID) | 广告曝光的具体位置,如QQ空间Feeds广告位。 |
| 站点集合ID(sitesetID) | 多个广告位的聚合,如QQ空间 | |
| 广告位类型(positionType) | 对于某些站点,人工定义的一套广告位规格分类,如Banner广告位。 | |
| 联网方式(connectionType) | 移动设备当前使用的联网方式,取值包括2G,3G,4G,WIFI,未知 | |
| 运营商(telecomsOperator) | 移动设备当前使用的运营商,取值包括中国移动,中国联通,中国电信,未知 |
接下来的任务就是从这些给的数据里面挖掘有用的信息去训练模型预测转化率啦。
3. 主要流程
这是Kaggle上数据挖掘比赛的黄金流程图:
我们也是采用这个流程来做的~
4. 数据分析&清洗
4.1 数据分析
拿到数据第一件事就是要好好分析数据!!!不仅一开始要分析,训练完也要根据结果分析,所以数据分析是要贯穿整个流程的,只有通过不断的分析统计,才能挖掘到数据背后的价值啊~
上面介绍数据表的时候已经有了一部分简单粗暴的分析了,实际上拿到赛题的时候进行的数据统计和分析远比上面的多,比如还统计了广告主上传回流时间的分布,上传回流时间在5,4,3,2,1天内的百分比,用户转化时间段分布各维度转化率情况(比如各广告主、广告计划、性别、年龄、app的转化率等等)…….
这些都是数据清洗和特征工程的依据。
4.2 数据清洗
按天对训练集train.csv转化率进行了统计

其中19号可能由于节日等原因导致转化率有点高,但是考虑到如果去掉这一天的数据就会丢失大一部分信息所以最终没有去掉。
而由于回流时间的存在,最后四天的数据会不准确,也就是说后五天的数据中有一部分实际上是转化了的,但广告主还没有来得及将这条转化汇报给广告系统,导致数据集中的label被误标记为了0(实际上是1)
这里我们尝试了两种方法:
- 根据经验猜测回流数据是广告主网站反馈回来的,所以我们计算了各广告主在最后五天内的最后一次回流反馈时间,将各广告主最后一次回流返回时间之后的数据删除掉这样就在一定程度上减少了不准确的负样本。这样筛去了大概有3万条。这样的做法带来的问题是有一些真正的负样本也被去除掉了。
- 由于最后两天数据的问题比较大,所以干脆直接把最后两天的数据删掉,不用这两天的数据训练模型,这样带来的问题是有一些在这两天新上线的广告就没有得到充分的训练。
5. 特征工程
一开始的时候我们采用了很多基本特征,即各种基础的category型特征(AppID, UserID, creativeID, pisitionID等)的onehot编码,又对单特征进行了一定的统计,比如某广告的转化率,某种联网方式的转化率等。后来看了大神“为情所困的少年”的分享,才反应过来其实无论是onehot还是对ID单维度的统计特征,其实都是对于一个特征的一种表达,从一定意义上是重复的。我个人感觉onehot之后的稀疏特征更适合于线性模型,如LR;而统计量的连续特征更适合于树模型,如GBDT。
回头来看,其实特征工程需要根据模型预先选择方向。李沐说过,模型是使用离散特征还是连续特征,其实是一个“海量离散特征+简单模型” 同 “少量连续特征+复杂模型”的权衡。既可以离散化用线性模型,也可以用连续特征加深度学习。就看是喜欢折腾特征还是折腾模型了。通常来说,前者容易,而且可以n个人一起并行做,有成功经验;后者目前看很赞,能走多远还须拭目以待。
后来这两种思路在初赛和决赛中我们的都尝试了:
5.1 海量离散特征+简单模型
在初赛的开始阶段,我们将各种基础的category型特征进行onehot编码,然后构造了一些单维度的统计特征,比如某广告的转化率,某种联网方式的转化率等,然后构造了一些组合特征,将这些特征onehot之后输入了LR模型就开始训练和预测了。
对于LR这种线性模型来说,它更适合于onehot类型的特征,首先它对于稀疏高维特征处理是无压力的,其次离散化后的特征对异常数据有很强的鲁棒性,这些在参考文献2逻辑回归LR的特征为什么要先离散化中可以看到。
对于一些onehot之后维度很大的特征,我们通过统计,取高频的一部分,舍弃低频的一部分,进行onehot。但随着构造特征的增多,onehot之后的向量维度剧增,这时就会带来维度灾难问题,见参考文献4机器学习中的维度灾难。不仅如此,这时基本上也就被设备问题限制死了。
这很烦。于是我们就换模型了。
5.2 少量连续特征+复杂模型
既然要预测的是转化率,我们不如把特征转化为转化率特征,这样特征就变成了连续值,同时我们还抽取了一些统计特征,比如某广告在一天之内、n天之内的点击量,转化量,某用户历史安装次数、APP历史被安装次数,等等,然后输入树模型中训练。感谢“为情所困”大神的分享,树模型比LR快了不少。
5.3 组合特征构造
说到特征组合,从统计的角度解释,基本特征仅仅是真实特征分布在低维空间的映射,不足以描述真实分布,加入组合特征是为了在更高维空间拟合真实分布,使得预测更准确。
在初赛和决赛阶段,我们共使用过两种组合特征的表达:
1. 对离散ID进行hash生成新特征
在初期用LR的时候,我们采用的方式是hash。即对两个ID做hash运算,得到一个新特征。这是一个很巧妙的方法。例如下面这个表,我们做哈希:
age×10+gendarage×10+gendar
得到第三列:
| age | gendar | hash |
|---|---|---|
| 1 | 0 | 10 |
| 2 | 1 | 21 |
| 3 | 2 | 32 |
第三列的的特征的取值有两位,十位是age,个位是gendar。新特征是一种新的交叉特征的体现。
2. 对组合进行统计生成新特征
像之前“为情所困”大神说过的那样,其实无论onehot还是统计特征,其实都是对于一个特征的一种表达。因为后期我们采用了GBDT,因此我们弃用了之前的hash组合方式,而选用统计量(即点击量、转化量和转化率)。这样就在一个维度上表达了这两个特征的组合,而且非常便于计算。
实现:按字段groupby,获取统计量和转化率特征
5.4 特征选择
我们用到了两种特征选择的方法:
- 根据方差:方差很小的属性,意味着该属性的识别能力很差。极端情况下,方差为0,意味着该属性在所有样本上都是一个值,所以我们尽量选那些方差比较大,区分度比较好的特征。
- 根据模型评分+相关系数矩阵:用GBDT训练会得到一个特征打分,可以作为筛选特征的依据,与此同时,我们发现,有一些特征之间有很强的相互作用,比如加入了某个特征之后会使之前排名很靠前的特征下降,因此我们还计算了特征之间的相关系数,对于相关系数较大的特征,我们就多次试验,反复选择
特征之间的相关系数:


另外,“酱紫”学长对特征筛选还有一种建议就是直接对所有基本特征进行遍历两两组合,然后用卡方检验筛出来一些比较好的特征。这种方式很简单,大多数工作只需要交给模型来完成。日后学习一下
5.5 用户-APP特征挖掘
特征说到这里,还有两个表没有充分利用上,user_app_actions.csv 和
user_installedapps.csv
user_app_actions.csv :用户安装app流水,1——30天的,包含安装时间,既然包含安装时间,就可以提取出用户的偏好安装时间、类别、app的偏好安装时间、安装量等特征
user_installedapps.csv 用户历史安装app
两个表都有用户和APP的安装信息,所以是否可以提取出用户和app之间的一些联系呢。思考一个问题,如果用户已经点击了某个APP的广告,那么是否会转化(下载)取决于什么呢?除了一些客观的因素,比如广告位(是否误点),联网方式等,当然是用户到底感不感兴趣!需不需要!
想到这里就感觉是个推荐系统方面的问题了,所以我们查了一些资料,尝试了用三种方式表达用户和app之间的联系:
tf-idf向量特征
- 把用户看成文档,app、app所属的类别看成词
- 把app、app所属的类别看成文档,用户看成词
没什么提高
word-embedding特征
user_app_actions.csv中包含用户的近期下载的app,根据时间可以得到app下载的顺序。把word2vec应用在用户app下载序列上,根据用户下载app的顺序,把app看做单词,也是可以形成这样的序列数据,进而训练处每个app对应的向量,看作是app的一个特征。
SVD分解
user_installedapps.csv表中没有时间信息,也就不合适用word2vec来提取特征了,我们想到了用推荐系统中的常用套路:SVD分解关于SVD知识的补充日后可以看下面两篇文章:
5.6 贝叶斯平滑
这里我们参考了@王照彬 大神的平滑方式
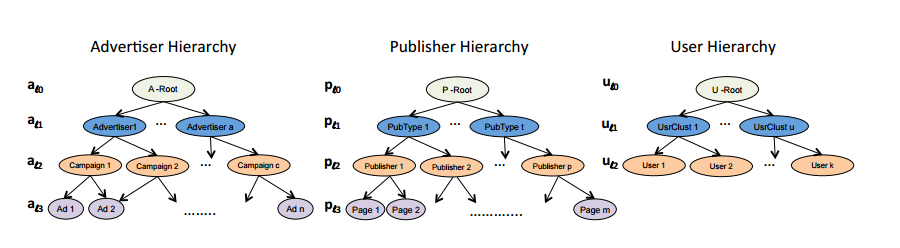
例如对我们数据中存在的 root -> advertiser -> campaign -> ad -> creative 层级关系(root为训练集中全部样本), 这样的层级关系隐喻了在同一个父节点下的子节点, 其来自于同一个Beta分布, 所以我逐层进行了贝叶斯平滑, 且建立层级关系还有一个好处, 即对预测集出现的数据, 若该creativeID 在训练集从未出现过, 则在pandas.merge时该值为空, 则向上寻找其父节点的统计值, 最高一层为root, 是基与全部训练数据的统计, root的值不进行贝叶斯平滑, 且一定存在, 这就保证了当在预测集中遇到了未出现的样本时, 使用最合理的缺省值进行补全.
关于贝叶斯平滑,其核心思想就是说,当某些广告投放量比较少时,或者还未投放时,根据历史数据所统计的转化率特征是不准确的,比如有广告A和B,,,由于广告A的投放量还比较少,通过历史数据计算而得的 就很有可能不准确,在比如如果某一个广告还未投放过,那么根据历史数据计算其转化率为0,放入模型中训练,也是非常不合理的,所以我们该如何解决呢?
对于贝叶斯平滑参数的估计方法,可以采用矩估计、极大似然估计和EM算法,这里由于速度的限制,我们采用的是矩估计的方式,代码TencentAD_contest
关于贝叶斯平滑,有待补习,参考文章:
5.7 多线程抽取特征
决赛数据集太大,而我们组合特征非常多。因此我们采用了多线程抽特征的方式。
每个特征一个进程,同时对多个特征进行抽取。
代码见TencentAD_contest,extra_rate_thread_0623.py
5.8 总结
竟然有这种操作队分享总结得非常好,我们的特征主要分为以下几类:
Trick特征:
重复点击的数据条目:通过观察原始数据是不难发现的,有很多只有clickTime和label不一样的重复数据,按时间排序发现重复数据如果转化,label一般标在头或尾,少部分在中间,在训练集上出现的情况在测试集上也会出现,所以把重复点击数据中的第一条和最后一条标记出来,让模型去学习。后来进一步标注,非重复数据0,重复但不是第一条和最后一条1,重复且是第一条2,最后一条3。这里面包含用户的重复点击、creativeID的重复点击等
时间差特征:与重复第一条的时间差和重复最后一条的时间差特征,与前一条和后一条的时间差,甚至包括了重复组合特征的时间差特征
rank特征:重复数据的rank特征,同样包括重复的用户、广告等
这里实现方面用到了pandas的
shift()操作,非常酷炫
统计特征(单维+组合):
原始特征主要三大类:广告特征、用户特征、位置特征,通过交叉组合算统计构造特征,由于机器限制,统计特征主要使用了转化率,部分特征还统计了点击次数和转化次数。前面已经说过,就不详细列举。用户app行为挖掘特征:
word-embedding特征、SVD特征
最后附上当时的特征评分表:

6. 训练集/测试集构造
尝试过两种方法:
滑动窗口
用每天的前七天的统计(统计指统计转化量、点击量、转化率,下同)来作为本天的特征。
这样就得到了24-30号7天的特征数据,再加上31号的特征,然后用24-29做训练,得到模型,30号作为线下验证集合,验证模型的线下loss,然后将31号的特征输入到该模型,得到最终的线上预测结果,提交。
如下图所示:
经测试我们发现,即使我们去掉了30号的部分负样本,还是有一些问题的,30号的数据还是不够好,线上线下会不一致,因此我们改用28号做验证:
这样做出于两种目的:一是尽量做到了线上线下统一,二是不让模型学习30号的样本数据,防止一些错误样本被模型学到。用第一周统计,第二周做交叉验证并训练模型。如下图所示:

相信很多人都用的是这两种其中的一种。我是一个对自己极度不自信的人,来来回回换了好几次。最终觉得第2种方式很稳定,线上线下较统一。第1种方式特征更新较快,模型更准确,但带来的问题就是线上线下不太统一。
7. 模型训练&验证&调参
7.1 模型
操作系统:ubuntu14.04
机器内存:256G
语言:python
用到的模型:
LR:L1\L2
gbdt:xgboost,lightGBM
gbdt+lr:Facebook论文中提出的一种方法
特征离散化+ffm:
可以参考我的两篇文章
7.2 调参:
决赛LGB参数:
|
初赛XGB参数:
|
8. 项目代码
9. 参考资料
- Kaggle 数据挖掘比赛经验分享
- 逻辑回归LR的特征为什么要先离散化
- 特征哈希(Feature Hashing)
- 机器学习中的维度灾难
- 【特征工程】特征选择与特征学习
- 描述量选择及特征的组合优化
- scikit-learn系列之特征选择
- GBDT原理及利用GBDT构造新的特征-Python实现
- 很好的文献资料Facebook CTR Paper
- 竟然有这种操作队分享
- 【SPA大赛】腾讯广告点击大赛:对stacking的一些基本介绍
- 第七名
10. top3方案
10.1 top1
特征工程非常细致,而且有理有据,都是经过仔细的分析统计抽取的特征,效果必然好,而且还做了模型创新,用

10.2 top2
也是用了17-30号交叉验证,和我们相同的就不说了,说说不同的:
回流数据不准处理方法:删掉30号平均回流时间较长的数据
应该是这里回流的处理方式比较好,特征也比较细致,最后模型也做了stacking,模型大概跟我们差不多,但是我们ffm一直没训练好,最后也没有融合
10.3 top4
deepFM